

Building a local AI-powered Summarizer chat
- Published on
- Reading time
- 11 min read
- Category
- The Sandbox
Last year, I wrote a blog post about an experimental local AI model that’s running inside the Google Chrome browser. While this API was experimental and is now not available anymore, the Chrome team has announced a few new variants of this API. Chrome split it into several specialized APIs, each with its own focus and capabilities.
And one of them is already available in stable Chrome versions and even built into this very website. If your browser supports the Summarizer API, you’ll see a ✨ button in the bottom-right corner. This opens a small chat interface where you can interact with the Summarizer API. This will then summarize the content of the article you’re currently reading. And the coolest part is that it’s all done locally on your device, without any data being sent to external LLM providers, costing me nothing to provide this feature.
So let’s see how it works!
What is the Chrome Summarizer API?
The Chrome Summarizer API is part of Chrome’s Built-in AI suite. Unlike “traditional” LLMs that require API keys and are running on servers in huge data centers, these are running completely offline on your device. That’s also why it’s not available for everyone, as not every device has the necessary hardware to run these models. Also it’s not built into every browser at the moment, as you can see here in the baseline status:
Summarizer
Limited availabilitySupported in Chrome: yes. Supported in Edge: yes.
Supported in Edge: yes. Supported in Firefox: no.
Supported in Firefox: no. Supported in Safari: no.
Supported in Safari: no.
This feature is not Baseline because it does not work in some of the most widely-used browsers.
But once it’s available for you it is a really cool little feature that can help some users quickly screen articles to see if they’re interested in reading the full version. Or if you have a documentation for something and want to give your users a quick overview over the content.
When using it you can choose between a few different types of summaries:
- TLDR: Comprehensive summaries for quick understanding
- Key Points: Bullet-point style highlights of main topics
- Teaser: Engaging previews to spark interest
- Headlines: Concise titles and subject lines
In addition, you can specify the length of the summary (short, medium, or long) and also the format (plain text or markdown). This makes it easy to customize the output to fit your needs.
One thing to keep in mind is that the summarizer can only do what the name suggests: summarize text. It cannot generate new content or provide additional information. You can also not chat with it directly but can just provide text to summarize (although there is also a Prompt API planned). So you cannot compare it to a chatbot like ChatGPT or Gemini.
Enabling the Summarizer API
See debugging information
Since the API is available starting with Chrome 138, you can start using it right away without needing to set any flags.
But if you want to check the current status or see some debugging information, you can navigate to chrome://on-device-internals.
Once enabled, this shows you information like your device performance class, event logs or some model information.
You can see whether a model is downloaded, which version is installed, and how often it has crashed.
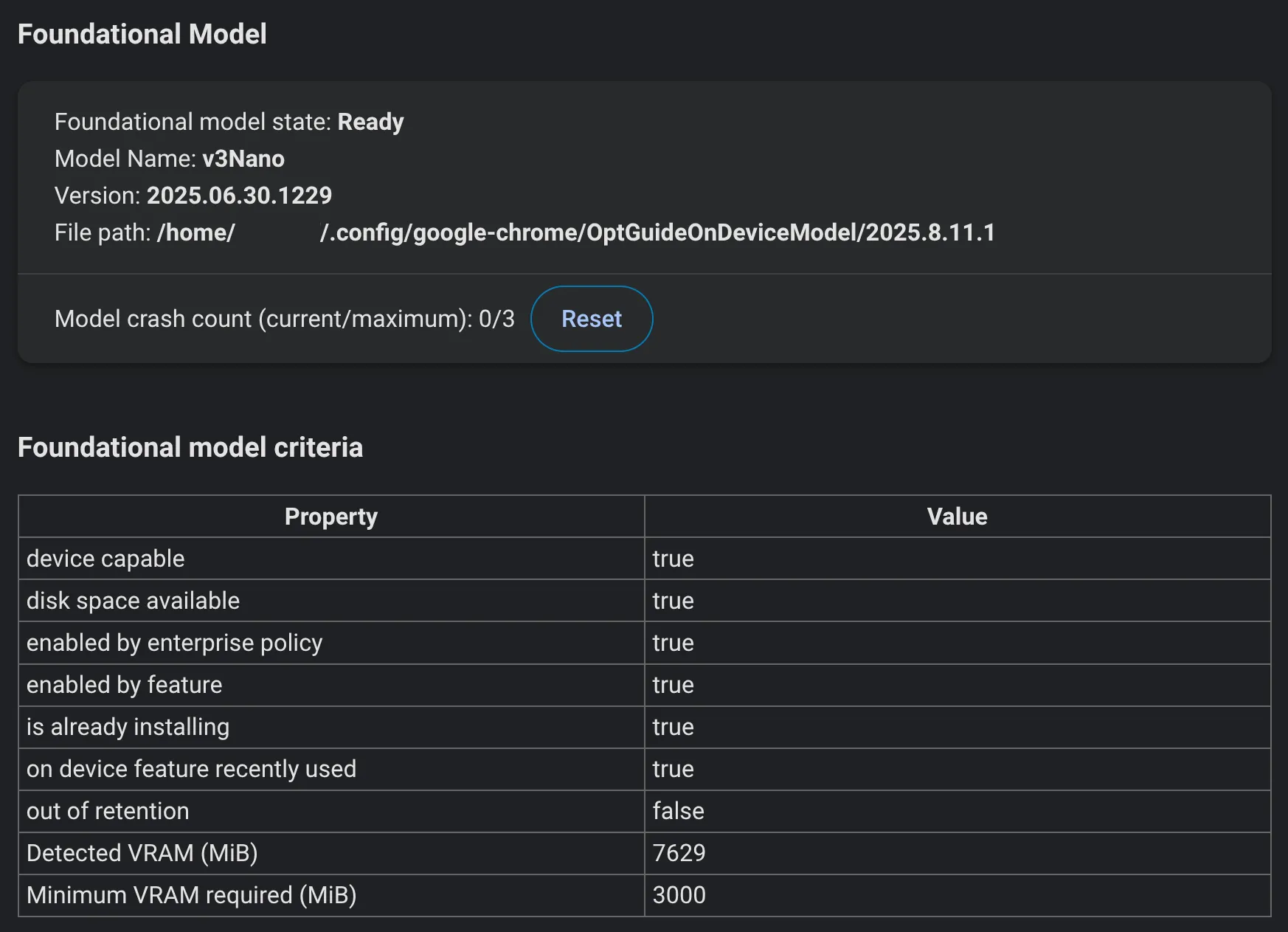
Unfortunately the model is not at all stable in my testing, depending on the device. So you might need to reset the crash counter, if you want to try again. But once it’s working it’s super interesting!
Check model availability and download
Before you can do anything with the Summarizer, you need to check if the model is available. You can do this by calling:
const availability = await Summarizer.availability();This returns one of the following values:
unavailable: The model is not available on your device.downloadable: The model is ready to be downloaded.downloading: The model is currently being downloaded.available: The model is available and ready to use.
When you then want to download the model, you can just create a new instance of the Summarizer which will automatically start downloading the model.
const summarizer = await Summarizer.create({
monitor(m) {
m.addEventListener('downloadprogress', (e) => {
console.log(`Downloaded ${e.loaded * 100}%`);
});
}
});And then it’s time to wait ⏳. Although the Gemini Nano model is smaller than cloud-scale models like GPT-5 or Claude, it still requires a multi-gigabit download (~4GB on my machine).
But now that it’s downloaded we can finally start using it. So let’s see how the summarizer chat is built.
Building the Chat Interface
I split the implementation into two separate parts:
- Chat Component: This part handles the user interface and interaction logic.
- Chat Management: This part handles the state, including model availability, download progress, the actual summary generation and the chat history.
Chat Component
The chat component itself is super simple:
export default function Chat() {
// Early return if API is not available
if (!("Summarizer" in self)) {
return null;
}
const [isOpen, setIsOpen] = createSignal(false);
const {
messages,
availability,
downloadProgress,
isGenerating,
generateSummary,
} = createSummaryChat();
// ... rest of component
}The component first checks if the Summarizer API exists in the global scope.
This ensures that the chat is not even shown if the API is not available to a user.
If it is available, we need to handle the open / closed state so we can toggle the chat visibility (this is just a default SolidJS signal). And then afterwards we can initialize the summary chat, which we’ll take a look at soon.
One thing we still need to do though is to parse the messages.
Since I didn’t just want boring text messages, I use the markdown output of the AI model.
So we need to parse the markdown, which is done using the marked library and then sanitize it with the DOMPurify library.
DOMPurify.sanitize(
marked(message.content, { async: false, gfm: true }),
);And that’s already it for the component. I won’t bore you with the details of the component HTML itself, since this is just a default SolidJS component and the styling is completely up to you.
It’s way more interesting to see how the state is managed and how to interact with the AI model.
Chat State Management
As said, the core functionality lives in my custom createSummaryChat hook that manages:
- Messages: Array of chat messages from both user and AI
- Availability: Current status of the AI model
- Download Progress: Progress indicator when the model is downloading
- Generation State: Whether the AI is currently processing a request
export function createSummaryChat() {
const [availability, setAvailability] = createSignal<Availability | undefined>();
const [downloadProgress, setDownloadProgress] = createSignal(0);
const [isGenerating, setIsGenerating] = createSignal(false);
const [messages, setMessages] = createSignal<Array<ChatMessage>>([
{
id: crypto.randomUUID(),
actor: "ai",
content: "Hey there 👋!\n\nI'm an AI assistant 🤖 running **offline inside your browser**..."
},
]);
// ... implementation
}Creating a Summarizer Instance
Before generating summaries, we need to create a summarizer instance:
async function createSummarizer(type: SummaryType): Promise<SummarizerInstance | undefined> {
const availability = await Summarizer.availability();
setAvailability(availability);
if (availability === "unavailable") {
// Handle unavailable state
return undefined;
}
return Summarizer.create({
sharedContext: "This is a blog about web development topics and programming experiments...",
type,
format: "markdown",
length: type === "tldr" ? "long" : "medium",
monitor: (monitor) => {
monitor.addEventListener("downloadprogress", (event) => {
setDownloadProgress(e.loaded);
});
},
});
}First you need to check if the model is available at all. Then we need to decide what to do: If the model is completely unavailable, we cannot generate a summary so we cannot proceed. In any other case we can create our summarizer instance. This will automatically download the model and update the progress bar if it’s not already downloaded. Once the model is available, a new session is created and we can start summarizing stuff.
But as you can see, I already pre-configured my session with the following options:
- sharedContext: Provides context about the content and some rules how the summary should be generated (like a system prompt)
- type: Determines the style of summary (
tldr,key-points,teaser) - format: Output format (I want to use markdown to allow additional formatting)
- length: Controls summary verbosity (
short,medium,long) - monitor: Callback for tracking model download progress
Generating Summaries
Now that we have a way to create a summarizer instance, we can finally generate our first summary.
async function generateSummary(type: SummaryType): Promise<void> {
// Create summarizer instance
const summarizer = await createSummarizer(type);
if (!summarizer) return;
// Extract content from the current page
const postContent = document.querySelector(".post-container")?.innerText;
setIsGenerating(true);
// Generate summary
const summary = await summarizer.summarize(postContent);
// Add summary to messages
setMessages((messages) => [...messages, {
id: crypto.randomUUID(),
actor: "ai",
content: summary,
}]);
setIsGenerating(false);
}While this works, it’s also kind of boring. You need to wait ⏳ for ages again, until the model finishes the complete summary and only then it’s displayed.
Streaming Summaries
So let’s do it like nearly all AI chat interfaces and enable real-time streaming. This will update the UI for each chunk of text that is generated, so we can already read the first output while the model is still working on the summary.
async function generateSummary(type: SummaryType): Promise<void> {
/* Prepare summarizer and data */
const stream = summarizer.summarizeStreaming(postContent);
let content = "";
let messageId = "";
for await (const chunk of stream) {
// Add new chunk to existing content
content += chunk;
if (!messageId) {
// Create new message for first chunk
messageId = crypto.randomUUID();
setMessages((messages) => [...messages, {
id: messageId,
actor: "ai",
content,
}]);
} else {
// Update existing message with new content
setMessages((messages) =>
messages.map((message) =>
message.id === messageId ? { ...message, content } : message
),
);
}
}
/* Clean up */
}This creates a more interactive and engaging experience for users, not having to wait for the entire summary to load before seeing any progress 🚀.
Try It Yourself
If you have some recent version of Google Chrome installed on your pc (no it’s not available on mobile), you may already see the ✨ button in the bottom-right corner of this page. Have fun trying it out!
For everyone not using Chrome or being on mobile, I made a small demo. This just outputs the same summary that was generated by the model on my machine once during writing.
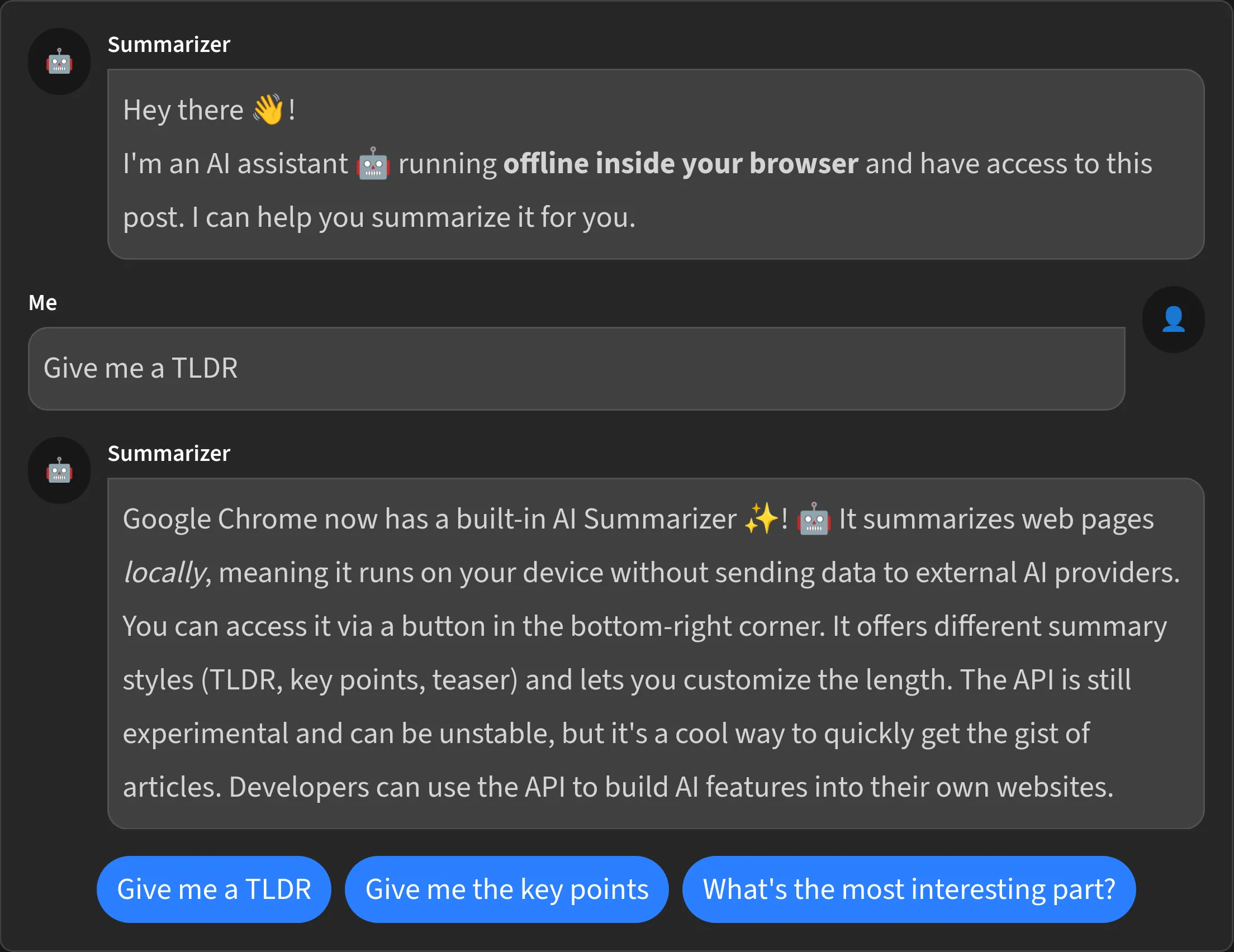
Summary chat that summed up this article in different styles. This is not live and uses pre-defined texts.
As said, this is just a small demo and the model is not very stable in my opinion (at the time of writing).
There is also a demo playground by Google if you want to try out summarizing your own texts, or play with the different parameters like length, type, etc.
What Works Well
- Offline Operation: No network requests after initial model download
- Fast Response Times: Summaries generate in 10 seconds typically
- Decent Quality: While not on par with professional tools, it can in fact summarize text
- Streaming: Real-time token generation feels responsive and is super satisfying to use
Current Limitations
- Browser Support: Only Google Chrome with powerful enough hardware
- Model Size: Initial download takes some time and may not complete at all
- Stability: Depending on the device it didn’t work at all, though this already got better with updates
Looking Forward
The Chrome Summarizer API is an exciting new feature that makes building AI into web applications more accessible. I personally don’t want to pay AI providers so that users can use these features on my sites (especially since I don’t make money off of them). So this is a great opportunity for developers like me to experiment with AI without worrying about costs.
But I also have some wishes for the future:
- Broader Browser Support: Other browsers adopting similar APIs (as I’m a Firefox user myself)
- Improved Models: Better quality and efficiency over time
- Enhanced APIs: More AI capabilities beyond summarization (Prompt API for interactive chats with my articles…🤔)
For now, it’s a fascinating experiment that showcases the potential of local AI.
Try the chat component on this page if you have the right browser setup, and experiment with different summary types. The future of local AI in the browser is here - it just needs a bit more time to mature.
Latest Post
Related Post
Integrating local AI into Rainbow Palette
Google announced a local Gemini Nano model inside Chrome that can be used by websites directly in the browser. I tried to integrate this experimental feature into Rainbow Palette to generate color palettes. Let's see how it works and how you can use it yourself!
- Published on
- Category
- The Sandbox